[Kafka]카프카 기초/개념 정리하기
by EastGlow
개요 및 개념
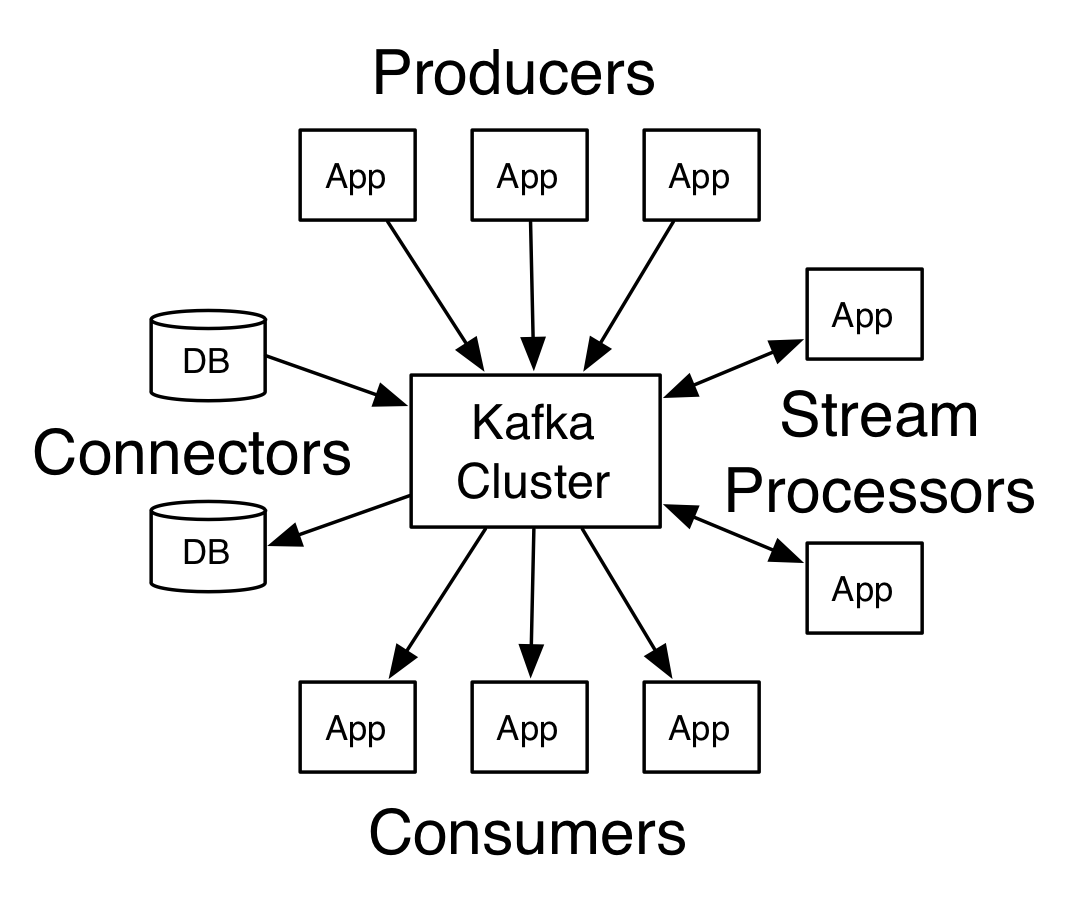
- 2011년 링크드인에서 여러 구직 및 채용 정보들을 한 곳에서 처리(발행/구독) 하기 위해 만든 플랫폼으로 시작
- 분산형 스트리밍 플랫폼(A distributed streaming platform)
- pub-sub 모델은 발신자가 수신자에게 직접 메시지를 전달하는 구조가 아니라 발신자가 특정 Topic에 메시지를 발행(pub)하면 수신자가 직접 해당 토픽을 구독(sub)하는 방식을 이용한다. 때문에 기존 메시지 큐 시스템보다 성능적으로 더 우수하다.
- 기존 메시지 큐 시스템처럼 메모리에 메시지를 저장하는 게 아니라 파일에 저장한다.
- 카프카를 재시작해도 메시지 유실 우려가 적어진다.
- 하드 디스크의 순차적 읽기 성능은 메모리에 비해 크게 떨어지지 않는다. (하드디스크의 순차적 읽기 성능은 메모리에 대한 랜덤 읽기 성능보다 뛰어나며 메모리의 순차적 읽기 성능보다 7배 정도 느리다. 물론 하드디스크의 랜덤 읽기 성능은 메모리의 랜덤 읽기 성능보다 10만 배나 느리다.)
- 메시지를 메모리에 저장하지 않기 때문에 메시지가 JVM 객체로 변환되면서 크기가 커지는 것을 방지할 수 있고 JVM의 GC로 인한 성능 저하 또한 피할 수 있다.

Topic
- 발행된 메시지들에 대한 (=분류되는) 하나의 카테고리나 피드명
- Topic은 항상 다중 구독자를 가진다. = 한 Topic은 0부터 1 이상의 많은 Consumer를 가질 수 있다.
Partition
- Topic이 저장되는 공간, 단위
- Consumer Group 당 오로지 하나의 Consumer만이 한 Partition에 접근할 수 있다. 즉, 한 Group 내의 여러 Consumer들이 한 Partition에 같이 접근할 수 없다.
Offset
- 0부터 1씩 증가하는 순차 증가 값
- 각 Partition 내에서 메시지를 식별하는 고유 ID 값으로 사용된다.
- Offset 값은 Partition마다 별도로 관리되므로 Topic 내에서 메시지를 식별할 때 Partition 번호와 Offset 값을 통해 식별할 수 있다.
Producer
- 메시지를 발급, 생산하는 주체
Consumer

- 메시지를 구독, 소비하는 주체
- 일반적으로 Consumer 개수와 Partition 개수는 같게 한다. 이유는 하나의 Partition에는 한 Consumer만 데이터를 읽을 수 있기 때문에 Consumer가 더 많다면 그 Consumer는 놀게 된다.
Consumer Group
- 하나의 Topic을 읽는 Consumer들을 묶는 집합
- 혹시라도 하나의 Consumer Group에 문제가 생겨서 데이터를 못 읽게 되더라도 다른 Consumer Group에서 대신 읽을 수 있게 되어(Rebalancing, 리벨런싱) 장애 상황에서도 문제없이 대처할 수 있게 된다.
Broker, Zookeeper, Cluster

- Broker는 Kafka Cluster에서 실행되는 Kafka 서버
- Cluster는 많은 Kafka Broker로 구성된다.
- Zookeeper는 분산 메시지 큐 정보, Cluster를 관리해주는 역할
Replication Factor
- Replication Factor 수를 통해 Topic의 Replication을 몇 개로 할지 정할 수 있다.
- Topic별로 설정 가능하다.
- Replication 수가 많을수록 Broker 장애 발생 시 Topic에 저장된 데이터 안정성이 보장된다.
Leader, Follower

- Replication 된 것들 중 대표 역할은 Leader, 나머지는 Follower
- 만약에 Leader에 문제가 생기면 나머지 Follower들 중 하나가 Leader 역할을 맡게 된다.
[참고자료]
https://kafka.apache.org/
http://cloudurable.com/blog/kafka-architecture/index.html
https://team-platform.tistory.com/11
https://epicdevs.com/17?category=460351
https://www.popit.kr/kafka-%EC%9A%B4%EC%98%81%EC%9E%90%EA%B0%80-%EB%A7%90%ED%95%98%EB%8A%94-topic-replication/
Kafka 도입 사례와 예시
- 네이버 TV연예 서비스의 사용자 소비 데이터 분석 : https://d2.naver.com/helloworld/7731491
- 링크드인(LinkedIn) : LinkedIn news feed와 LinkedIn today에서 활동 데이터 스트리밍 처리에 사용
- 데이터시프트(DataSift) : 이벤트를 모니터링하기 위한 수집기와 사용자의 데이터 스트림 소비를 실시간으로 추적하는 추적기에 사용
- 트위터(Twitter) : 카프카를 Storm의 일부로 사용
- 포스퀘어(Foursquare) : 온라인 - 온라인, 온라인 - 오프라인 메시징에 카프카 사용. 모니터링, 실 운용환경, 하둡기반의 인프라스트럭처 연동에 사용
- 스퀘어(Square) : 모든 시스템 이벤트를 데이터 센터와 실시간 경고 시스템으로 보내는데 사용
- IBM 메시지 허브(IBM Message Hub) 베타 : Streaming Analytics 1/1000초 이하의 응답시간과 즉각적 의사결정을 돕기위한 초당 수백만 건의 이벤트 분석에 사용
- 간단한 분산 트랜잭션 구현 : https://www.popit.kr/rest-%EA%B8%B0%EB%B0%98%EC%9D%98-%EA%B0%84%EB%8B%A8%ED%95%9C-%EB%B6%84%EC%82%B0-%ED%8A%B8%EB%9E%9C%EC%9E%AD%EC%85%98-%EA%B5%AC%ED%98%84-3%ED%8E%B8-tcc-confirmeventual-consistency/
[참고자료]
https://pubdata.tistory.com/30
https://wooyoung85.tistory.com/32
기타
ListenableFuture
public void sendMessage(String message) {
logger.info(String.format("#### -> Producing message -> %s", message));
ListenableFuture<SendResult<String, String>> future = this.kafkaTemplate.send(TOPIC, message);
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onSuccess(SendResult<String, String> result) {
System.out.println("Sent message=[" + message +
"] with topic=[" + result.getRecordMetadata().topic() + "], partition=[" + result.getRecordMetadata().partition() + "], offset=[" + result.getRecordMetadata().offset() + "]");
}
@Override
public void onFailure(Throwable ex) {
System.out.println("Unable to send message=["
+ message + "] due to : " + ex.getMessage());
}
});
}
- Producer에서 KafkaTemplate을 통해 메시지를 보낸 후 callback 처리를 할 수 있게 도와준다.
- 리턴받는 SendResult에서 해당 메시지의 Topic명과 Partition 번호, Offset 번호를 알 수 있다.
- onSuccess, onFailure를 Override하여 사용한다.
- public void onSuccess(SendResult<String, String> result)
- public void onFailure(Throwable ex)
Subscribe via RSS