[Java]Selenium으로 Visual SVN History 크롤링 하기
by EastGlow
사내에서 다른 팀과 뭔가 공유하거나 주고 받을 필요가 있을 때 사내 Visual SVN 서버를 이용하곤 한다. 그런데 업무 중에 이 SVN 서버에 Commit된 History가 필요하여 어떻게 가져다 쓸 수 있을까 생각하다보니 크롤링을 해올 수 있을 거 같아서 그냥 크롤링 되는 정도까지만 간단히 만들어보았다.
1. 준비물
- Spring Boot 2
- Selenium
- geckodriver.exe (https://github.com/mozilla/geckodriver/releases)
뭐 항상 그랬듯이 Spring Boot로 간단하게 프로젝트를 만들어준다. Spring Boot로 프로젝트 만드는 건 이전 포스트에서도 다뤘었고 어느정도 그런 것을 아는 사람들이 볼 거 같은 글이라 생략하겠다.
그런 다음 pom.xml에 아래 의존성을 추가해준다.
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.141.59</version>
</dependency>
그리고나서 로컬 PC에 Firefox를 깔아준다. Firefox가 크롤링할 때 가장 환경을 안 타고 무난하게 쓰기 좋다고 하더라. 또한, 위에 링크 걸어둔 geckodriver.exe도 받아준다. 들어가서 64bit zip 파일을 받아서 압축 풀면 exe 파일이 하나 나올텐데 프로젝트 내부에 위치시키든지 로컬 PC의 원하는 곳에 위치시키든지 한다. 이게 있어야 Selenium의 WebDriver와 Firefox가 상호작용할 수 있다고 한다. 즉, Selenium과 Firefox가 서로 연동될 수 있게 해주는 드라이버이다.
Java에서 쓸 수 있는 Selenium 의존성 라이브러리이다. 원래 Jsoup을 이용해보려 했는데 Visual SVN의 웹 페이지에 접근하려면 Windows 인증 정보창을 거쳐야 한다. Jsoup으로 이걸 뚫을 수 있는 방법이 있는지 Stackoverflow에도 찾아보고 물어보고 했는데 답이 안 나와서 결국 Selenium을 사용하게 되었다.
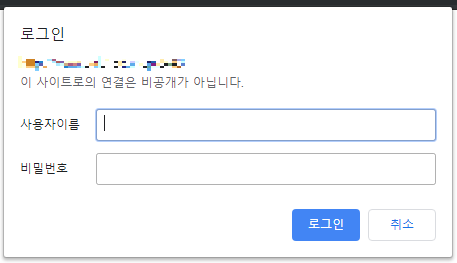
위 사진처럼 Visual SVN 웹 페이지로 접근하려면 Windows 인증 정보창이 뜨게 된다. Visual SVN에 등록된 User라면 해당 User의 아이디, 비밀번호로 인증하고 들어갈 수 있다.
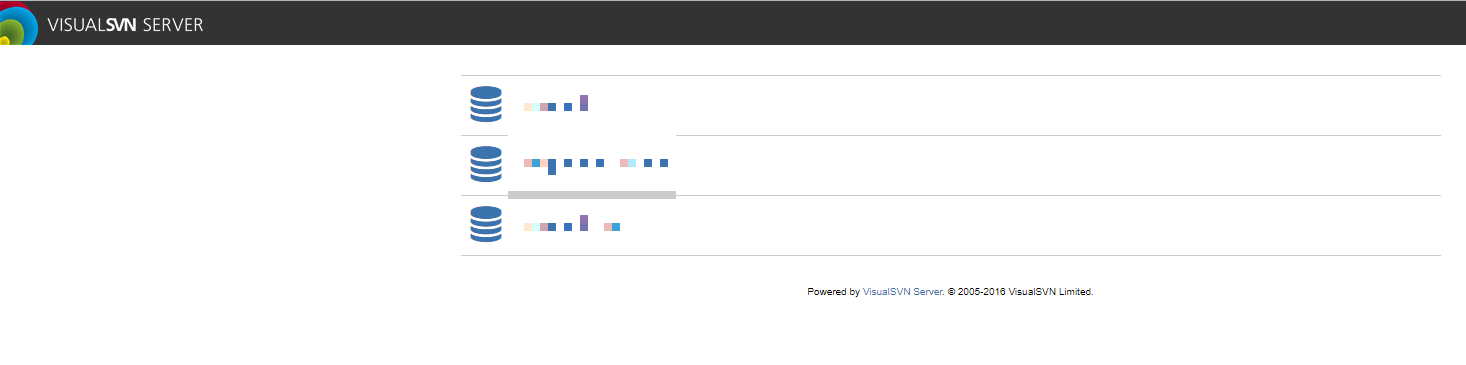
들어오게 되면 Visual SVN Server에 생성된 저장소들이 나오고 저장소를 클릭하여 들어가면 저장된 파일 리스트와 커밋 히스토리를 볼 수 있다.
2. 어떻게?
저 커밋 히스토리를 어떻게 들고올까… 곰곰히 생각해봤는데 크롬 개발자 도구로 구조를 살펴보니 커밋 히스토리 div에 id 값이 매겨져 있었다.
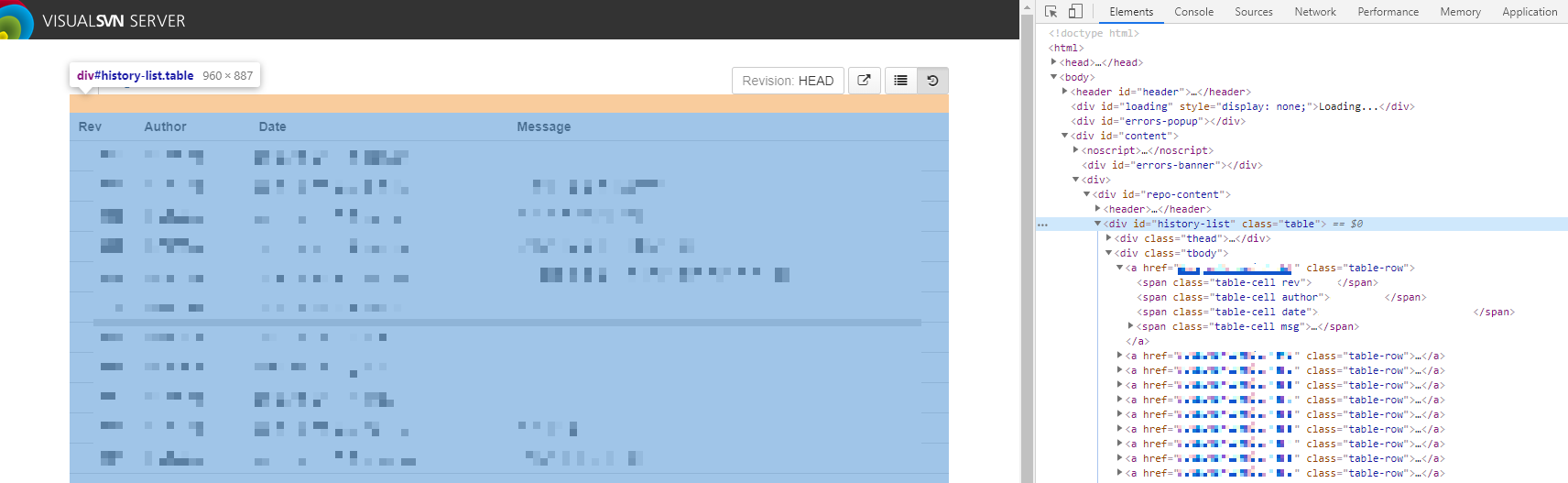
`오… 저 div id 값을 기준으로 div를 뽑아와서 잘 조합하면 되겠구나’ 싶어서 얼른 해보았다.
여기에서 전체 소스를 확인할 수 있다.
package me.eastglow.controller;
import me.eastglow.service.MainService;
import lombok.extern.slf4j.Slf4j;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.openqa.selenium.firefox.FirefoxOptions;
import org.openqa.selenium.firefox.FirefoxProfile;
import org.openqa.selenium.support.ui.ExpectedConditions;
import org.openqa.selenium.support.ui.WebDriverWait;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.GetMapping;
import javax.annotation.Resource;
@Slf4j
@Controller
public class MainController {
@Resource
private MainService mainService;
@GetMapping("/main")
public String main(Model model) {
String URL = "http://svntest.com:443/!/#myrepo/history";
System.setProperty("webdriver.gecko.driver", "D:\\workspace\\svn-history-crawling\\src\\main\\resources\\static\\geckodriver.exe");
FirefoxProfile profile = new FirefoxProfile();
profile.setPreference("permissions.default.image", 2);
profile.setPreference("permissions.default.stylesheet", 2);
profile.setPreference("dom.ipc.plugins.enabled.libflashplayer.so", false);
FirefoxOptions options = new FirefoxOptions();
options.setHeadless(true);
options.setProfile(profile);
WebDriver wd = new FirefoxDriver(options);
wd.get("http://test:test@svntest.com:443");
wd.get(URL);
WebDriverWait wait = new WebDriverWait(wd, 3);
WebElement first = wait.until(ExpectedConditions.visibilityOfElementLocated(By.id("history-list")));
model.addAttribute("contents", first.getAttribute("innerHTML"));
return "main";
}
}
위 소스처럼 /main을 호출하면 설정한 SVN 웹 페이지의 History 페이지를 긁어오고 거기서 #history-list에 해당하는 div 엘리먼트를 가져오게 된다.
여기서 중요한 부분은 wd.get("http://test:test@svntest.com:443");부분이다. 위에서 말했듯이 SVN 웹 페이지에 접속하려면 Windows 인증 과정이 필요한데 여기엔 계정 이름과 비밀번호가 필요하다. 이부분을 해결하기 위해서는 주소 앞에 @를 써주고 계정이름:비밀번호를 붙여주면 알아서 로그인이 되어 통과된다.
브라우저 세션이 살아있는 한 로그인을 한번 했으니 그 다음은 어느 페이지를 가도 로그인이 다시 필요하지 않게 된다. 그렇게 로그인을 하고 난 뒤에 이제 진짜 우리가 원하는 History 쪽 URL로 접근을 하면 된다.
여기서도 한가지 내가 시행착오가 있던 부분이 있었는데 원래는 그냥 바로 Element를 id 값으로 검색하여 가져왔는데 그렇게 하니깐 자꾸 id 값에 해당하는 div를 못 찾는 것이었다. 구글링해보니 로딩되는 시간을 조금 기다려주고 난 뒤에 id 값으로 검색하도록 하면 될 거라고 하였다. 그래서 WebDriverWait라는 객체를 만들어서 History 페이지를 긁어올 때 조금의 시간을 두어 로딩이 끝날 때를 기다렸다가 가져오도록 하였다.
그것을 JSP로 내려서 그대로 찍어보니 아래 그림과 같이 History 내역을 잘 긁어오는 것을 확인할 수 있었다.
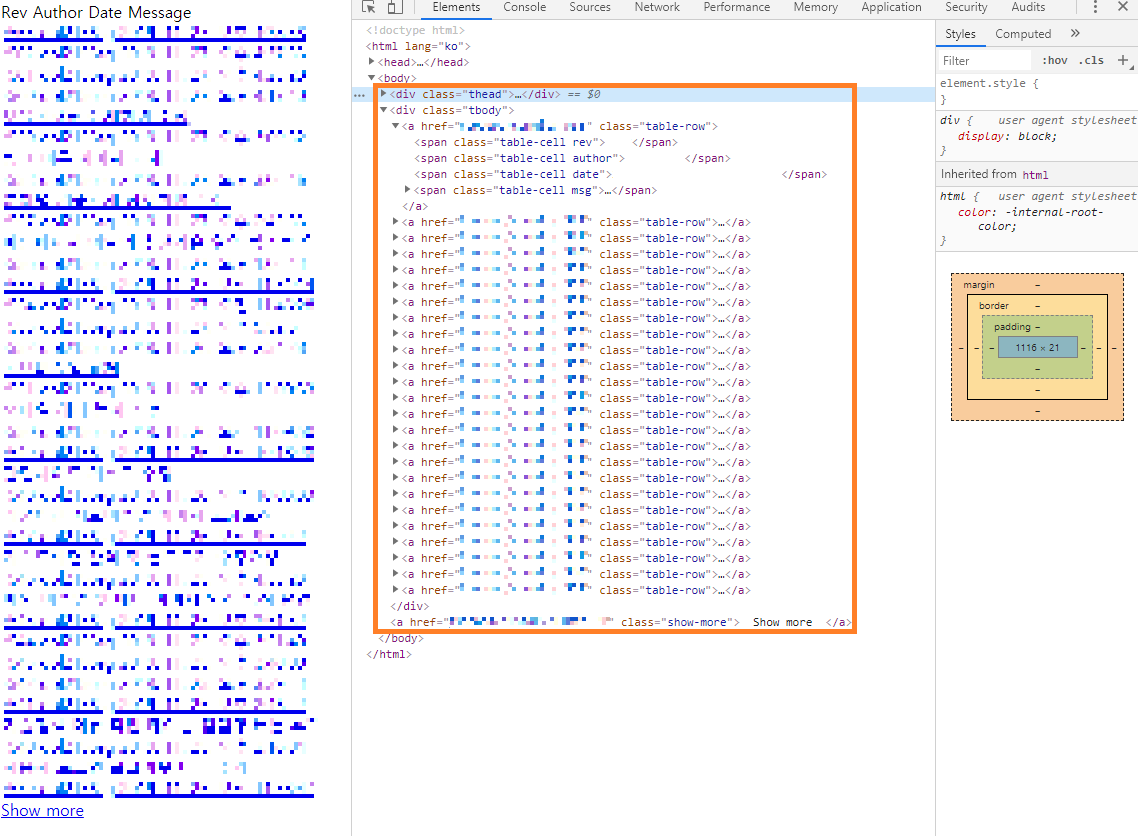
나는 일단 딱 SVN History를 긁어오는 것까지 했기 때문에 이후에 이것을 어떻게 가공을 하든 DB에 넣든 그건 더 생각해봐야할 거 같다. Visual SVN 자체에서 API 같은게 있으면 좋겠지만 찾아보니 없어서 간단하게 Selenium을 통해 History를 크롤링해오는 것을 해보았다.
Subscribe via RSS